
« 海量数据库设计经验与研究-暨中韩技术交流会 | Blog首页 | DBA手记:从10g到12c,JOB的问题auto_space_advisor_job_proc »
DBA手记:Cache-Low RBA与On-Disk RBA的恢复

链接:https://www.eygle.com/archives/2011/02/cache_low_rba.html
在最近(2010年9月6日)的一次培训中,有位朋友问起上节案例,该如何证明和验证Oracle介于Cache-Low RBA和On-Disk RBA之间的恢复过程?我们可以通过如下的过程来做一些观察和证明。
首先执行一个建表的CTAS操作,这个操作是为了多生成一些脏块(Dirty Buffer),然后紧接着执行两次控制文件转储,两次转储是为了确认对比一下控制文件的检查点没有变化,然后紧接着执行强制关闭数据库(Abort方式),再启动数据库:
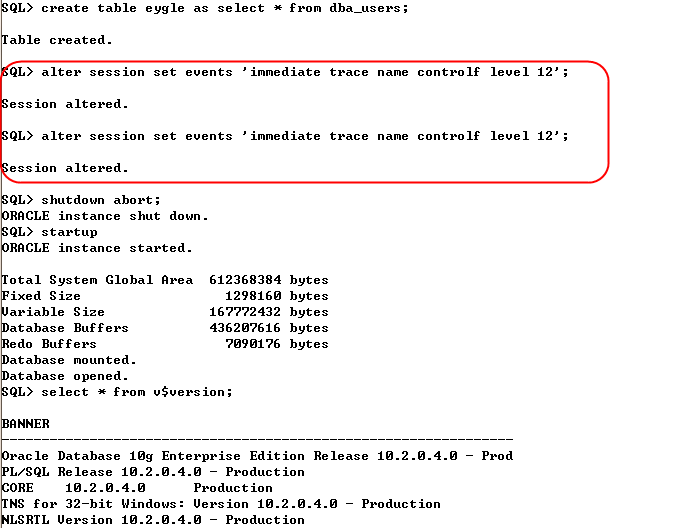
现在来分析一下跟踪文件,看看其中的相关信息,选取第二次转储的控制文件信息,在数据库Entry部分,可以找到检查点记录:
***************************************************************************
DATABASE ENTRY
***************************************************************************
(size = 316, compat size = 316, section max = 1, section in-use = 1,
last-recid= 0, old-recno = 0, last-recno = 0)
(extent = 1, blkno = 1, numrecs = 1)
07/31/2010 16:35:48
DB Name "ENMO"
Database flags = 0x00404000 0x00001000
Controlfile Creation Timestamp 07/31/2010 16:35:49
Incmplt recovery scn: 0x0000.00000000
Resetlogs scn: 0x0000.00089c75 Resetlogs Timestamp 07/31/2010 16:35:52
Prior resetlogs scn: 0x0000.00000001 Prior resetlogs Timestamp 03/14/2008 18:46:22
Redo Version: compatible=0xa200300
#Data files = 4, #Online files = 4
Database checkpoint: Thread=1 scn: 0x0000.00119459
Threads: #Enabled=1, #Open=1, Head=1, Tail=1
此时记录数据库的检查点SCN是119459,这是16进制,10进制是1152089。
继续检查,在检查点进程记录部分,获得如下信息,这里就包含了Low Cache RBA和On Disk RBA的信息,也记录了Dirty Buffer的数量是48:
***************************************************************************
CHECKPOINT PROGRESS RECORDS
***************************************************************************
(size = 8180, compat size = 8180, section max = 11, section in-use = 0,
last-recid= 0, old-recno = 0, last-recno = 0)
(extent = 1, blkno = 2, numrecs = 11)
THREAD #1 - status:0x2 flags:0x0 dirty:48
low cache rba:(0x27.6c.0) on disk rba:(0x27.f9.0)
on disk scn: 0x0000.001195a5 09/10/2010 14:55:25
resetlogs scn: 0x0000.00089c75 07/31/2010 16:35:52
heartbeat: 729376761 mount id: 570757625
把这里的RBA信息简单分析一下:
|
|
RBA信息 |
Log Sequence |
Blcok Number |
|
Low Cache RBA |
0x27.6c.0 |
0x27 = 39 |
6c=108 |
|
On Disk RBA |
0x27.f9.0 |
0x27=39 |
F9=249 |
在启动数据库时,进行恢复产生了一个跟踪文件,记录了恢复的过程,恢复从39号日志文件的第108块恢复至249块,正是以上数据库关闭之前的RBA地址范围:
*** SESSION ID:(158.4) 2010-09-10 14:56:11.738
Successfully allocated 2 recovery slaves
Using 545 overflow buffers per recovery slave
Thread 1 checkpoint: logseq 39, block 2, scn 1152089
cache-low rba: logseq 39, block 108
on-disk rba: logseq 39, block 249, scn 1152421
start recovery at logseq 39, block 108, scn 0
----- Redo read statistics for thread 1 -----
Read rate (ASYNC): 70Kb in 0.20s => 0.34 Mb/sec
Total physical reads: 4096Kb
Longest record: 8Kb, moves: 0/243 (0%)
Change moves: 2/29 (6%), moved: 0Mb
Longest LWN: 53Kb, moves: 0/6 (0%), moved: 0Mb
Last redo scn: 0x0000.001195a4 (1152420)
----------------------------------------------
数据库恢复的检查点起点是SCN 1152089,也就是控制文件中记录的数据库最后完成的检查点,On-Disk RBA的SCN是1152421,转换为16进制也就是1195A5,也和控制文件中记录的On Disk SCN完全相符。
数据库的恢复SCN范围也就由此确定,即SCN范围:1152089~1152241。
启动数据库之后,查询一下日志信息,可以看到39号日志文件正是执行恢复的日志文件,其SCN范围处于1152088和1172422之间,一个日志就满足了之前恢复的SCN范围,恢复完成之后日志切换,当前使用了40号日志:
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME
------ ------- ---------- -------- ------- --- -------- ------------- ------------
1 1 40 52428800 1 NO CURRENT 1172422 10-SEP-10
2 1 38 52428800 1 NO INACTIVE 1131823 10-SEP-10
3 1 39 52428800 1 NO INACTIVE 1152088 10-SEP-10
至此我们清晰地看到了数据库恢复从Low Cache RBA至On Disk RBA的过程。
历史上的今天...
>> 2012-02-24文章:
>> 2008-02-24文章:
>> 2006-02-24文章:
>> 2005-02-24文章:
By eygle on 2011-02-24 08:19 | Comments (0) | Backup&Recovery | Internal | 2734 |