
« Oracle数据恢复:格式化,Raid损坏,文件覆盖恢复 | Blog首页 | 《Oracle数据库性能优化》一书发布计划 »
关于Freelists和Freelist Groups的研究

链接:https://www.eygle.com/archives/2011/11/freelistsfreeli.html
一. 什么是freelists
本文在于探讨Freelists和Freelist Groups的作用,存取机制,争用诊断和优化方法,同时通过理论和测试来推翻一些存在了很久的错误观点。本文的读者应该具有较深入的Oracle知识,对于一般的开发人员这篇文章可能并没有太多的帮助。
我们知道Oracle数据库的读取单位是数据块(Block),而一个Block是否允许被写入数据是基于一定的空闲度,这就是大家知道的pctfree和pctused存储参数设置。
假设pctfree=10, pctused=40,这就表明当一个Block的空间使用率达到了90%(100-pctfree)时,这个block就不再允许被用于新增数据(insert),而保留下来的这10%的空间则被预留为行更新(update)所可能需要的空间扩展,我们说此时这个block就从freelist上被摘走了(实际上还有另外一种情况,就是当块剩余空间不足以插入一条记录并且该块的使用率已经超过了pctused定义的值并且该块位于freelist header处时,该块也会从freelist上被摘走,术语称为UNLINK)。当有数据删除(delete)的时候,只有该block中的数据被删除到一定的程度,该块才会重新被加入到freelists中,而这个程度就是pctused参数定义的数值,如我们这个例子中,只有块中的数据降低到40%以下的时候,该块才被重新允许用于新增数据。
通过上面的描述,可以知道所谓freelists,就是一个指定了所有可以用于insert操作的数据块的列表。存在在这个列表中的数据块才能用于insert操作,一旦一个数据块无法用于insert(达到了pctfree参数指定的限度)则立刻从这个列表中被摘除。freelists的作用就在于管理高水位标志(HWM)以下的空闲空间。
注意:freelists只是管理高水位标志以下的空闲空间,而实际上一个segment可用的空闲空间包括两种类型:
1. 已经分配给这个segment但是从来未被使用过的位于高水位标志之上的blocks
2. 位于高水位标志之下,被链接在freelists上的blocks
至于freelist groups的概念和作用,在下面的章节适当的地方会解释。
二. freelists是否已经过时
随着Oracle9i的推出,对于空闲块的管理变得更加智能和有效率了。在LMT(Locally Managed Tablespaces)中如果指定了ASSM(Automatic Segment Space Management),那么对于任何pctused,freelists,freelist groups存储参数的指定都将被忽略。创建ASSM表空间的方法如下:
CREATE TABLESPACE lmtbsb DATAFILE '/u02/oracle/data/lmtbsb01.dbf' SIZE 50M
EXTENT MANAGEMENT LOCAL
SEGMENT SPACE MANAGEMENT AUTO;
ASSM得益于使用位图(bitmaps)来管理段中的空闲块,至于具体是如何管理的,那又是另外一篇文章了。
就此意义上来说,对于freelists的探讨确实可能已经有些过时了,但是首先并不是所有的数据库现在都已经升级到了Oracle9i,甚至在最需要调整的一些大型应用上往往都由于业务的稳定性而不愿意冒升级到新版本的危险;其次即使是新的应用使用了Oracle9i数据库,如果数据库管理员在创建表空间的时候没有明确指定SEGMENT SPACE MANAGEMENT AUTO,那么默认情况下仍然会使用Freelists和Freelist Groups来管理Free Block。
所以,在仍然存在有大量Oracle8i数据库和非自动段空间管理表空间的现在,对于freelists的研究仍然具有很实际的意义,而由于默认的freelists和freelist groups又都只有1,所以又恰恰是高负载的应用中最需要调整(Tuning)的部分之一。
三. freelists存储在哪儿
freelists存储在每个segment的header block中,我们可以通过dump来得到更清楚的认识。dump在研究oracle的内部机制时通常都扮演着很重要的角色。
假设我们创建一个表空间TS_TEST,此表空间是非自动段空间管理的,然后在该表空间中创建T_MANUAL,T_MANUAL_FREE2,T_MANUAL_FREEGROUP2三张表。这三张表的freelists和freelist groups设置如下。
SQL> select SEGMENT_NAME,SEGMENT_TYPE,FREELISTS,FREELIST_GROUPS from USER_SEGMENTS where TABLESPACE_NAME='TS_TEST';
SEGMENT_NAME SEGMENT_TYPE FREELISTS FREELIST_GROUPS
-------------------- ------------------ ---------- ---------------
T_MANUAL TABLE 1 1
T_MANUAL_FREE2 TABLE 2 1
T_MANUAL_FREEGROUP2 TABLE 4 2
则可以参照下面的方法对segment header block进行dump操作。
首先先从数据字典中得到存储这个segment的文件号和此segment的第一个block号(也就是segment header block)
SQL> select FILE_ID,BLOCK_ID from dba_extents where segment_name='T_MANUAL';
FILE_ID BLOCK_ID
---------- ----------
7 9
使用dump命令转储这个block的内容,转储的结果将保存在初始化参数user_dump_dest指定的目录中。
SQL> alter system dump datafile 7 block 9;
System altered
查看user_dump_dest目录中的相应trace文件,我们可以看到包含如下几行:
frmt: 0x02 chkval: 0x0000 type: 0x10=DATA SEGMENT HEADER - UNLIMITED
表示这个block正是segment header block。
#blocks in seg. hdr's freelists: 2
#blocks below: 2
表示位于freelist中的数据块有2个,在高水位标志(HWM)下的数据块也有2个。
SEG LST:: flg: USED lhd: 0x01c0000a ltl: 0x01c0000b
由于我们dump的是TS_MANUAL表的header block,而这张表的freelists=1,所以在dump文件中看到只有一个seg lst,这个freelist被称为segment free list或者master free list,每个segment都至少有一个而且只有一个master free list(当然是在非自动段空间管理类型下)。
flg(flag)表示该freelist是否被使用
lhd(list header)表示位于该list中的第一个可用block的dba(Data block address)
ltl(list tail)表示位于该list中的最后一个可用block的dba,这个block必定位于HWM之下。
此时我们可以发现freelists只是记录了这个segment中空闲块的第一个块地址和最后一个块地址,在第一个空闲块的块头处(block header)记录了它之后的下一个空闲块的地址,而下一个空闲块又记录了再下一个空闲块的地址,由此依次记录,一直到最后一个空闲块。Oracle通过这种链表的方式实现了freelists对于空闲块的管理。

注意:每次当一个block被加入到free list中时,该block会被放置在free list的链表头部。
同样我们可以dump第一个空闲块来验证上面的链表说法。
比如在lhd部分记录的dba是0x01c0000a,这是一个16进制的数,首先转化为10进制,于是得到29360138。然后通过oracle提供的两个函数将块地址转化为可以供我们使用的文件号和块号,以便于我们进行dump操作。
SQL> select dbms_utility.data_block_address_file(29360138) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------
7
SQL> select dbms_utility.data_block_address_block(29360138) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------
10
现在我们已经得到第一个空闲块是7号文件的10号块。用前面提到的转储命令dump这个块的内容,我们可以找到下面的内容:
fnx: 0x1c0000b
表示下一个可用的块地址是0x1c0000b,在我们的例子这个块正好是可用的最后一个块(segment header block中的lhd部分),我们可以再次dump这个0x1c0000b块,同样查看转储的结果,找到下面的内容:
fnx: 0x0
0x0表示下面没有可用的空闲块了,也就是表明这是freelists中的最后一个空闲块。
注意:你们的测试可能得到跟我不一样的转储内容,这是正常的。
一. 有多少种free list
1. master free list或者segment free list
简称为MFL,在segment被创建的时候自动生成的,如果我们在创建segment时没有指定freelists参数,或者指定freelists=1,都是生成这个MFL。MFL对于每个segment来说有且只有一个(如果指定freelists>1,产生的就是不是MFL,这一点将在process free list部分解释)。MFL相当于一个空闲空间池,当一个segment被创建时的初始化block以及以后动态分配的新block都链接到MFL中,这个池中的所有空闲块是被所有进程共享的,对于该segment有insert操作的所有进程都可能会去读取这个free list,这样当有多个进程要同时insert数据时,就可能出现在MFL上的争用(MFL在一个时间只能允许一个进程取得空闲块,当然,其实进程从MFL上读取空闲块的操作并不是简单地需要多少就取多少,取得以后就直接向块中插入数据,实际上的过程要更复杂一些,这个过程在"进程请求空闲块的过程"部分会有详细描述)。由此,推出了freelist groups的概念,设置freelist groups参数大于1就是设置了多个MFL,这样就缓解了对于MFL的争用。有关freelist groups更详细的内容在"Super Master Free list"部分会有描述。
2. process free list
如果进程必须直接从MFL中读取空闲块,那么对于MFL的争用由freelist groups参数解决(设置多个MFL),但是显然还有另外一个思路就是尽量不让进程去直接读取MFL,没有需求自然就无所谓争用。由此引入了另外一个级别的free list,这就是process free list,简称为PFL。当我们指定存储参数freelists>1的时候,生成的就是PFL。
我们前面说过MFL是在segment被创建的时候自动生成的,所以无论是不是有PFL,对于每个segment来说都仍然存在1个MFL。也就是如果我们定义freelists等于2的话,那么在segment header block中将总共存在3个freelist,其中1个是MFL,另外2个是PFL。
这一点我们同样可以通过dump转储信息来验证。
SEG LST:: flg: UNUSED lhd: 0x00000000 ltl: 0x00000000
SEG LST:: flg: UNUSED lhd: 0x00000000 ltl: 0x00000000
SEG LST:: flg: USED lhd: 0x01c0008b ltl: 0x01c0008b
后面两个free list既是PFL,而前面一个则是MFL。
顾名思义,既然命名为process free list,那么显然位于这个级别的free list中的空闲块只能被一个进程读取。想象一下,如果当前系统对于某张表最多同时会有10个进程同时作insert操作,那么我们设置freelists=10,将能尽量满足每个进程都能够使用专属于自己的free list,无疑通过这样的手段我们缓解了free list的争用。
一个进程到底会使用哪个PFL,oracle内部的算法是:(P % NFL) + 1
其中P表示DML操作进程的Process ID,可以从v$process.pid字段中取得。
NFL表示freelists存储参数定义的PFL数量。
可能会有疑问,如果是这样,多个MFL有存在的必要吗?我们只需要设置多个PFL不就可以了吗?然而事实并非如此,不过请稍安毋躁,在后面讲解"进程请求空闲块的过程"中会解释这个问题。
3. transaction free list
在Oracle中事务(transaction)是一个重要的概念,每次DML操作,事务的开始都是自动的,而我们可以通过commit或者rollback来标志一个事务的结束。一个进程(或者说一个用户会话)有自己的PFL,然后一个进程可能会执行很多的事务,于是又出现了这个级别的free list,这就是transaction free list,简称为TFL。
TFL是动态产生的,只有当DML语句(比如delete或者update)使block占用量降到pctused参数指定值之下时才会生成TFL,一个TFL只属于一个事务,而一个事务也只会有一个TFL,一个事务没有提交之前,此事务的TFL上的空闲块不会被其它事务使用。但是可以立刻被本事务使用(此时这些空闲块被称为previously freed blocks)。
每个segment最少可以有16个TFL,同时只要有需求就会动态增加TFL数量,除非达到了segment header block size的限制。当没有空间允许新的事务得到自己的TFL时,这个事务就必须等待其它的事务提交并释放TFL。等待哪个事务的算法是:(P % NFL)
其中P表示DML操作进程的Process ID,可以从v$process.pid字段中取得。
NFL表示当前的TFL总数量。
通过dump转储数据块信息,我们可以看到类似于下面的内容:
XCT LST:: flg: USED lhd: 0x01c0008c ltl: 0x01c0008a xid: 0x0008.01f.000003d2
其中xid表示transaction id,关于transaction id的格式和表示的意义,有兴趣的读者可以查看其它的资料。
4. Super Master Free list或者Segment Master Free list
这个级别的free list只有在设置了多个freelist groups时才会出现。
当我们设置freelist group>1,就会产生freelist group block,这些block紧跟在segment header block之后,假设我们设置了storage(freelists 4 freelist groups 2),那么该segment的第一个块是segment header block,第2,3个块则都是freelist group block。
首先在segment header block中存在1个free list,这个free list就被称为Super Master Free list或者Segment Master Free list。
而在每个freelist group block中又都存着1个MFL,还存在4个PFL,每个freelist group block块的剩余空间则全部留给TFL使用。
在单个instance中进程选择freelist group的算法是(P % NFB) + 1 。
其中P表示DML操作进程的Process ID,可以从v$process.pid字段中取得。
NFB表示freelist groups 参数定义的Freelist Groups数量。
而在RAC环境中的算法则更加复杂,本文不作讨论了。
查看freelist group block的转储文件可以看到类似于下面的内容:
frmt: 0x02 chkval: 0x0000 type: 0x16=DATA SEGMENT FREE LIST BLOCK WITH FREE BLOCK COUNT
blocks in free list = 5 ccnt = 0
SEG LST:: flg: UNUSED lhd: 0x00000000 ltl: 0x00000000
SEG LST:: flg: UNUSED lhd: 0x00000000 ltl: 0x00000000
SEG LST:: flg: UNUSED lhd: 0x00000000 ltl: 0x00000000
SEG LST:: flg: USED lhd: 0x01c00116 ltl: 0x01c0011a
SEG LST:: flg: UNUSED lhd: 0x00000000 ltl: 0x00000000
二. 进程请求空闲块的过程
我们通过对两个事务的描述来说明进程请求空闲块的整个过程。
1.事务T1删除了表T中的一些数据,释放了这个segment的block 10中的一些空间。并且使block的已用空间降到pctused参数值以下,因此在segment header block中产生了一个T1的TFL,而block 10被link到这个TFL中。
2.事务T2想要插入一些数据到表T中。但是由于T1没有提交,所以block 10并不能被T2使用,而假定T2没有作过释放空间(delete或者update)的操作,所以T2也没有自己的TFL。
2.1.T2开始查找自己的PFL,尝试找到可以使用的空闲块(术语称为WALK)。假设在T2的PFL上有三个block:block 11,12,13,但是都没有足够的空间满足T2的需求。
2.2.假定block 11的已用空间超过了pctused参数值,而又由于无法满足T2需求,所以从T2的PFL上被摘除(术语称为UNLINK),同时free list header变为下一个block,也就是block 12(术语称为EXCHANGED),同样block 12不满足需求,又exchange到block 13,可惜的是block 13也同样不满足需求,于是T2的PFL上就没有可使用的空闲块了。
这个步骤的后台思想是当一个块在搜索空闲块的过程中失败,那么就不应该把这个块再放在free list header处。
注意:dead block的出现通常是由于设置了过高的pctused参数导致的。假设我们设置pctused=90,那么如果由于update等原因使一个block中的数据占用量降低了90%以下,这个block就立刻被重新link到free list中,但是很可能这一点儿空间根本就不允许insert一条记录,又因为此时的block占用量仍然位于pcyused参数值之下,所以即使这个block不满足插入一条记录的条件,也仍然被放置在free list header处。当进程需要free block的时候,会先查找这些块(默认最多查找5个块),如果都不满足insert的需求,才尝试提升HWM。
2.3.T2将PFL上的所有块都检查过,并且发现没有可用的,此时就停止查询PFL
2.4.Oracle尝试从MFL中移动空闲块到PFL中(术语称为Free Lists Merge)。移动的块数是一个常量-5个块。如果移动成功,那么从2.1步骤重新开始。
注意,此时Oracle不会去检查其它PFL,即使在其它的PFL上可能会有空闲块。
2.5.如果上一步中在MFL中没有找到可用的块,此时Oracle尝试从其它已经提交的事务的TFL中获取block。扫描header block中的TFL entries,查看是否又已经提交了并且链接有空闲块的TFL。如果找到,所有的空闲块都转移到MFL中。然后从2.4步骤重新开始。
2.6.如果上一步失败,Oracle尝试提升高水位标志(bump up HWM)。为了减少在segment header block上的争用,Oracle每次只提升m个block。m的算法是:
1:如果HWM<=4并且位于第一个初始化的extent上
5:未设置隐含参数_bump_highwater_mark_count时
min(_bump_highwater_mark_count * (PFL number+1) , unused blocks in the extent):设置了隐含参数_bump_highwater_mark_count时
2.7.如果上一步失败(HWM之上没有分配了但还未使用的block),则分配新的extent,新分配的在只有一个MFL情况下转移到MFL上,然后从2.4步骤重新开始。在有多个PFL(freelists>1)的情况下,则直接转移到申请空间的进程所拥有的PFL上,然后从2.1步骤重新开始。
3.事务T1准备向表T中插入新的记录。首先,它会检索自己的TFL上是否有空闲空间。由于block 10有可用空间,并且空间满足新纪录的需求,所以block 10将会被使用。
总结一下上面描述的过程。
当重新insert数据或者发生row migration的时候,会从TFL header处开始使用已经释放了的空闲block。如果TFL中没有 previously freed blocks,那么就从PFL中寻找,因为可能定义了多个freelist,所以到底从哪个free list中找,算法是前面描述过的(P % NFL) + 1。如果在PFL中找不到或者根本就没有PFL(segment只有一个freelist的情况),那么再从MFL中找。仍然找不到的话,返回去再查其它会话的TFL,判断其中的事务是否已经commit,如果已经commit了,则把这个TFL的flag标志为unused,同时把位于这个list中的所有block合并到MFL中。
如果经过上面的步骤,在任何一个级别的的free list中都没有找到可用的空闲块,此时segment就要提升HWM,如果提升HWM失败,则分配下一个extent,新分配的block被link到MFL或者PFL中,重新开始上面的查找步骤。
当一个块由于DML操作而被重新链接到free list中是被放置在MFL中的,如果有PFL存在,那么在使用前,根据数据请求量,每次最多转移5个block到相应的PFL中,也就是在存在多个freelist的情况下,一次空间的请求总是读取TFL或者PFL,而不会直接从MFL中读取。
现在我们可以回答前面的那个疑问了。
多个MFL有存在的必要吗?我们只需要设置多个PFL不就可以了吗?
从这个地方我们可以看到虽然多个free list可以缓解多个并发的session同时更新一个segment时对于data block的争用,但是如果只有一个main free list,那么在从main free list把block转移到process free list的这个环节上仍然会出现争用,此时就是多个freelist group发挥效果的时候了。所以多个freelist group不仅对于RAC环境有效,对于单个instance也是可以缓解一定的资源争用的。
但是如果有多个freelist group,就不可避免地会产生空间浪费的副作用,在某些特殊场合下甚至会让一个segment急速地增大,为什么会这样,可以参看后面关于freelist groups的那个比喻。
我们可以通过转储segment header block来查询HWM的位置,然后再查询转储freelist group blocks来查询link在每个free list上的空闲块,如果发现HWM的位置很高却又有大量的空闲块,就可能表示这个segment经历了不正常的extent扩展。
三. 块在free list间的移动
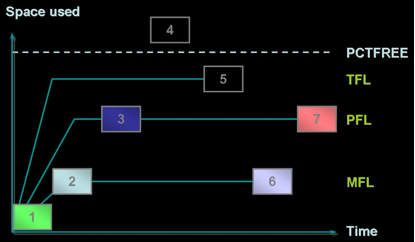
1.block被分配给一个segment,但是却不存在于free list中,因为这个block还位于HWM之上。
2.当block降到HWM之下时(bump up HWM),这个块就进入MFL或者一个free list group的MFL中。
3.如果设置了freelists>1,也就是存在多个PFL的情况下,block会进入PFL。有利于缓解对于MFL的争用。
4.当block的可用空间低于pctfree定义的值,block从free list中删除。此block不再被允许进行insert操作。
5.当一个事务进行了delete或者update操作,致使block的已用空间低于pctused定义的值,该块进入这个事务的TFL,除非事务commit,否则该块只能被此事务使用。
6.在寻找free block时,空闲块会从TFL转移到MFL
7.当用户进程需要空闲块时,空闲块又从MFL转移到PFL
一. 关于free list将导致大量空间浪费的误解
一直以来有的说法是多个freelist也可能会导致大量空间浪费,其实这是一个误解。至少从测试和某些更具有权威性的文档来看,多个freelist没有太多的空间浪费。
回顾一下一个事务请求空间的过程,我们就可以得出结论。
1.一个session需要空间了,先在自己的TFL上找,这是在找 previously freed blocks
2.找不到,找自己的PFL
3.再找不到,找MFL,如果找到,移动最多5个块到自己的PFL上,然后重新查找PFL
4.如果MFL中仍然找不到,返回去找其它会话的TFL,看看有没有commit了的事务,如果有,将这个TFL中的free block转移到MFL上(这个时候其它事务的free block就能被这个事务使用了),然后重复第三步。
5.所有的TFL上都没有空闲块,查找Super Master Free List,如果找到,将最多5个块转移到MFL上,然后重复第三步。
6.如果找不到,移动 HWM(Bump up HWM),如果成功,那么直接将块转移到自己的PFL上,重新查找PFL。
7.如果移动HWM不成功,那么分配extent,也就是分配新的block,重复第六步。
8.分配extent不成功,最终报错,没有可用的空间。
整个请求过程可以参看下图
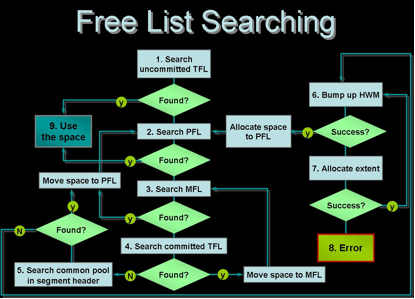
可见多个freelist只是多个process freelist而已,而main freelist始终只有1个,又因为main freelist是共享的,所有在同一个freelist groups中的process都可以从这个main freelist中取得free block,而每次取得的空闲块数也最多只有5个块,那么也就是一个PFL下不会链接过多的空闲块,同时当一个事务删除了大量的数据并且commit之后,这些空闲块是会归还给MFL,从而可以被其它事务使用。所以即使是设置了多个freelist,也并不存在多少浪费空间的问题。当然不论如何,设置了过多的freelist,终究是会浪费一些free block(即使可能只是浪费HWM之下的几十个block),而且还有一个坏处就是会减少可以分给TFL使用的free list entry,所以比较合适的设置是将freelists设置为最多可能同时操作该segment的会话数。
一. 对于freelists和freelist groups的一个比喻
对于freelist和freelist group,Tom在《Effective Oracle by Design》中有个比喻,非常形象。想象有一台饮水机和源源不断的急需喝水的人们,一台饮水机就代表一个free list,而一个想喝水的人就是一个准备向segment中插入数据的会话。如果我们只有一个饮水机,那么所有想喝水的人都必须要排成一队,然后前一个喝完了下一个才能喝,这就产生了争用。设想一下我们现在放置了10个饮水机,很明显人们可以排到10个队伍中的任何一个队伍里,毫无疑问效率大大加快了。这时瓶颈又出现了,就是如果一个饮水机里的水被喝完了,就得给这个饮水机加水,此时如果只有一个加水员(这就是一个freelist group),那么加水的速度可能就会跟不上了,添加freelist group就是增加加水员,增加到2个,每个人负责5个饮水机(体现在参数上,是freelists 5 freelist groups 2),OK,效率又提升了。
对于空间浪费的负面影响,我们继续设想一下。来了一个十分能喝水的人,他把住一个饮水机不停地喝,喝完了,引水员就加水,又喝完了,又加,即使是其它的9个饮水机里都是满满的水也没用,因为这个人一旦从某个送水员管辖下的饮水机中开始喝水,就不会换到另外一个送水员管理的饮水机上去(一个会话一旦从某个freelist group的freelist中开始读取空闲块,就不会再使用其它freelist group中的freelist,即使其它的freelist中还有很多的空闲块)。
二. 和freelists和freelist groups相关的等待事件
V$SYSTEM_EVENT视图中记录了从数据库启动以来所有的等待事件信息,通过这个视图我们可以比较清楚地知道数据库经历的最严重的等待到底是哪些。
但是一个等待事件可能会是由于各种各样的原因导致的,所以在检查V$SYSTEM_EVENT视图的同时还需要一些其它视图的辅助,才可以更准确地定位问题所在,比如我们可能还需要去查看V$SESSION_WAIT,V$WAITSTAT等视图。
跟freelists和freelists groups相关的等待事件中,比较主要的是Buffer Busy Waits事件和Enqueue事件。
1. Buffer Busy Waits
当一个进程需要一个数据块,但是发现这个数据块正在被其它进程读入buffer cache,或者说这个数据块虽然已经存在于buffer cache中但是却处于一个无法共享的状态,此时就经历Buffer Busy Waits等待事件。
通过检查V$SYSTEM_EVENT视图,可以确认系统是否正在遭受严重的Buffer Busy Waits事件(TIME_WAITED字段的值过大,表示等待总时长比较显著),但是这还不足以使我们能够判断到底问题出在什么地方,此时就需要再去检查V$WAITSTAT视图。这个视图中每一行都记录了系统经历的不同类别block的等待时间。通常如果我们发现segment header类别或者data block类别的等待时间显著,那么就很可能是freelists争用。
如果能够明白这两种类别的block等待产生的原因,自然就有相应的解决方法了。
首先解释一下为什么会产生segment header部分的等待。前文描述过如果没有使用多个free list group,那么所有的free lists都是位于segment header block中的。一个进程对于free list的操作将持有独占锁,如果多个进程同时请求操作free list,那么就会产生争用,而这个争用在V$WAITSTAT视图中就表现为segment header上的等待。
那么为什么会产生争用,这又有两种原因。
一种是同时要求操作free list的进程确实过多,这种情况下我们需要增加free list。
另外一种情况则是实际上同时操作的进程并不多,但是操作free list的频度过高,为什么会频繁操作,因为不停地有block从free list中被摘掉同时又不停有新的free block被放入free list中,这通常表示我们设置了不正确的pctfree和pctused参数值,比如pctused值和pctfree值设置的过近,这种情况下盲目增大free list可能并没有什么效果,我们需要作得是设置正确的pctused和pctfree值。
再来解释为什么会产生data block部分的等待。因为每个进程对于free block的请求都是从free list header处开始的,如果free list较少,那么无疑就增加了不同的进程取得的free block是同一个块的可能性。多个进程又去同时更新一个block,这就产生了data block的等待,这也是我们常说的热点块问题。由于热点块问题,同时在等待事件中可能比较显著的还会有latch free(Cache Buffers Chains Latches),latch又是oracle内部的另外一种锁定机制了,本文不再深入解释。
增加free list可以缓解这个问题,因为每个free block只会属于一个free list,给不同的进程分配不同的free list就减少了并发进程同时访问一个数据块的风险。
另外设法将被频繁并发访问的segment上的数据分布在更多的block中也可以缓解这个问题,比如我们可以增加pctfree值,以扩大数据分布。但是这就引出了另外一个问题,如何确定哪些数据块是热点块,只有知道了是哪些数据块,才可能知道这些块是属于哪个segment,才能有的放矢地调整相应segment的存储参数或者甚至将整个segment转移到另外的数据文件,另外的存储介质上。
由此引入另外一个视图,V$SESSION_WAIT。这个视图中存储的是一个会话实时的等待事件,如果我们只是偶尔去检查一次,可能正好捕捉不到buffer busy waits事件,所以应该通过计划任务(Oracle JOB或者操作系统级别的cron)定时地检查这个视图,将检查结果存入另外的表中,建议可以在系统繁忙期每隔5秒或10秒运行一次下面的SQL,注意取样的总时间不能过长,因为这个SQL对于系统还是有影响的。
SELECT /*+rule*/s.username, e.owner, e.segment_name, p1
"File#", p2 "Block#"
FROM v$session s, v$session_wait w, dba_extents e
WHERE w.event='buffer busy waits'
AND s.sid = w.sid
AND e.file_id = p1
AND p2 between e.block_id and e.block_id +(e.blocks - 1);
返回的结果中username表示读取这个块的用户名,owner表示拥有热点块所属segment的用户名,segment_name表示热点块所属的segment名称,File#表示热点块所处的数据文件号,Block#表示热点块号。
注意:如果我们使用Oracle10g,那么新增的性能视图-V$SESSION_WAIT_HISTORY将自动保留最近的10个会话等待事件的历史信息,通过这个视图可以更简单地判断问题。
如果我们设置了多个freelist group,那么我们在V$WAITSTAT视图中还可能会发现free list类别的等待,这个等待表示在freelist group blocks上产生了争用。注意,只有当设置了多个freelist groups时,才可能出现这个类别的buffer busy waits等待事件。至于调优的方法可以参看上面的调整手段。
2. Enqueue
enqueue也是一种锁(lock),只不过是oracle用来管理共享内存结构的锁定机制,通过enqueue来保证对于数据库资源的串行存取。
当我们在V$SYSTEM_EVENT中或者statspack报告中发现了严重的enqueue等待,首先需要确定的是系统在经历什么类型的enqueue等待。
如果我们使用了statspack,那么可以查看报告相应部分的enqueue等待详细信息。
或者也可以通过以下方法来确定enqueue类型。
运行下面的SQL,得到enqueue等待的相应记录。
SELECT username, event, p1, p2, p3
FROM v$session s, v$session_wait w
WHERE event='enqueue'
AND s.sid = w.sid;
返回结果中p1表示enqueue的类型和模式,p2和p3根据p1的不同有不同的含义。
注意:在Oracle10g之前,由于各种enqueue类型都显示为同样的enqueue等待,所以p2和p3的含义并不能从公开的文档中获得,而在10g中各种enqueue都显示为单独的enqueue等待,所以我们可以从V$EVENT_NAME视图的PARAMETER2和PARAMETER3字段中轻松获得每种不同eneque的p2和p3含义。
p1的返回值是10进制,转化为16进制以后,低2位表示模式,高2位表示类型。
现在我们假设p1= 1213661190,看一下如何通过这个数字得到enqueue的信息。
10进制:1213661190
转化为16进制:4857 0006
低2位:0006 => 模式(mode)是6,表示为Exclusive。
高2位:4857 => 将4857分成两个单字节,分别是48和57
将48和57转化为10进制:72和87
ASCII为72的字符:H
ASCII为87的字符:W
SQL> select chr(72)||chr(87) "enqueue" from dual;
enqueue
-------
HW
由此我们知道了现在经历的是HW enqueue等待,并且是独占模式(mode = Exclusive)。
我们也可以简单地使用下面的SQL直接获得enqueue的类型和模式。
select sid,
event,
p1,
p1raw,
chr(bitand(P1, -16777216) / 16777215)
||
chr(bitand(P1, 16711680) / 65535)
"TYPE",
mod(P1, 16) "MODE"
from v$session_wait
where event = 'enqueue';
跟freelists争用相关的enqueue等待常见的是HW。
当给segment分配新的extent时,将放置HW enqueue,如果有多个进程同时请求insert数据并且需要分配新的extent提升HWM的时候就会产生HW enqueue争用。通常发生在设置了多个的free list group的情况下。
如果为了避免freelists争用,而增加freelist group,确实可以减少Buffer Busy Waits事件,也会减少所有类别的block上的等待(从V$WAITSTAT视图中可以得知),但是却会增加HW Enqueu的等待事件。
因为一个进程使用了一个freelist group之后,即使其它的freelist group中有大量的空闲空间(比如一个进程刚刚删除了大量的数据,从而在自己的TFL上腾出了很多空闲块),这个进程也不会去检索。所以如果这个进程正好需要insert大量数据,那么就很可能会提升HWM,也就会放置HW enqueue,那么如果还有其它的进程也需要insert数据,就不可避免地经历HW enqueue等待。正是由于多个freelist group使提升HWM的几率变大,所以也就会导致HW Enqueue等待事件的增多。本章作者:张乐奕(Kamus)
历史上的今天...
>> 2014-11-24文章:
>> 2009-11-24文章:
>> 2006-11-24文章:
>> 2005-11-24文章:
By eygle on 2011-11-24 08:53 | Comments (0) | Internal | 2907 |