
« Oracle群英录 - 2013上海OOW名人录 | 文摘首页 | 吕海波(Vage)- 突然35岁:捡点我的职业生涯 »
吕海波(Vage)- 漂泊的技术人生 - ITPUB访谈录

本文引自ITPUB论坛,是Vage - 吕海波 的技术感悟,很有借鉴和学习意义,供参考。
原文链接:http://www.itpub.net/thread-1806151-1-1.html
----------------------------------------------------------------------------------------------------------------
arron刘:
大师您好,今天很高兴采访您,您先自我介绍一下? 分享一下您的职业经历? 您目前从事的工作?
VAGE:
我的ID VAGE,相信大家都知道了,经常发一些深奥、晦涩的文章,骗几篇精华赚赚人气。
其实并不是我总是发晦涩的文章。基本的原理啊、运行机制啊等等,这些年来大家都讨论的差不多了。现在不是流行"产业升级"这一说吗,这么多年了,我们研究Oracle的方法,也要"与时俱进"、"产业升级"吗。不能老是内部资料+各种DUMP。
我相信下一代专职DBA一定要掌握些软件调试技能,我的深奥文章,也就是调试技术在Oracle中的简单应用而已。就像N年前搞个10046就属于高精尖 了,我相信N年后我的文章只是入门级水平。就像现在的10046一样,如果现在你不懂得10046怎么用,还好意思说自己是DBA吗。
这次的OOW大会,很高兴看到Oracle将Solaris下优秀的调试工具Dtrace,移植到Oracle Linux下。其实几个月前我就已经得到这个消息,也第一时间试用了一下Oracle Linux下的Dtrace,功能当然没的说,但一些重要的探针(比如PID探针)Oracle Linux Dtrace下还没有,总的来说它还比较简单,期待以后版本中它进一步完善。
我的职业经历,这里就不详说了,在"35岁"那篇文章中:突然35岁:捡点我的职业生涯,已经有详细的介绍。
我目前在杭州博学负责Oracle的培训,同时还提供Oracle咨询服务。有需求可以联系我哦。除了这些表面上的工作,我在做的还有一件事,就是推广调试技术。我相信软件调试技术,将成为以后DBA的重要技能。
arron刘:
最近发布了12C版本,相信您已经尝鲜试用过了吧,能不能分享一下你的安装经验,谈谈12C和以前版本在安装上有什么不同的地方?
VAGE:
12C从安装上步骤上看,和11GR2基本类似,连安装界面都差不多,相信安装上不会有什么难题。我分享过一篇Solaris下12C安装问题的解决思路。
因为缺包,安装完成后Oracle可执行文件是0字界,解决方法很简单,relink all了一下,重新编译生成Oracle的可执行文件,问题解决。可以参见:12C安装历险记----ORA-12560和ORA-12537的解决方案。
安装其实很简单,从这个安例中,我更想分享的是一种解决问题的思路。希望对大家、特别是初级DBA有帮助。
arron刘:ORACLE 12C 应该是甲骨文公司的重量级产品,据说有500多项的更新,您能不能给我们讲讲Oracle 12c最主要的变化是什么?给我们分享一下你的使用感受呗。
VAGE:
变化,我觉得可以从两方面来说,一是功能,二是内部原理。
先说功能上的变化,12C新功能的确很多, 最大的亮点就是"Pluggable Database",PDB,"可插拔数据库"。网上已经有很多相关的文章,每一个PDB都是一个单独的小数据库,若干个PDB组合在一个大的CBD中, 共同构成一个大数据库。需要迁移数据的时候,可以将某个PDB拔出,插入进另外的CBD。这个特性,将使未来的数据迁移、数据流动更加方便。
还有ASM方面,ASM和数据库实例可以分别放在两台主机上。ASM和数据库实例的分离,至少说明Oracle以后有可能要为ASM添加更多的功能,如果ASM和数据库实例挤在同一机器,ASM功能太多,占用资源太多,势必会影响数据库实例的运行。
而且,分离之后,ASM就有点像存储的控制器了。存储控制器通过网络把LUN输送给主机,ASM通过网络,把DiskGroup输送给数据库。
还有,至得一提的时,12C中Oracle开始对EM做减法,推出了轻量级EM,安装简单、占用资源少,问题也更少。使用轻量级EM,将大大方便DBA们 的操作。但同时,图形化、智能化工具的普及,也必将提高DBA的要求。未来DBA必将向"一专多能"方向发展,但要注意,千万不能只"多能"。有"一专" 为基础的"多能",是如虎添翼。我还是哪句话,当水涨上来时,我们只有爬的更高。
另外,从内部原理、运行机制上说,Oracle也有不小的变动。Oracle从来没有停止精益求精的步伐。比如,12C下LGWR已经可以有多个,多 LGWR无疑将大大提高并发事务量。为达到这个目的,Oracle必然对Redo这块的机制有很大的变动,Redo这块的调优、排故,方法必然会有变化, 以往的经验有可能不再适合。
还有,以前在9i时代,我就觉得Buffer Cache池、共享池已经非常完善了,这一块原理基本不会发生变化了。到了10G,Buffer Busy Waits就发生了变化。还有,Mutex的出现,对共享池的锁机制做了很大的改动。12C后,Mutex、IMU等技术继续优化、完善。举个简单的例 子,Oracle获得共享Mutex的函数是kgxShared(已验证在Linux和Solaris下都是这个函数),在Oracle的可执行文件 中,11.2.0.1下,这个函数的大小是1496字节。而在12C中,这个函数大小缩减到393字节。(注:只需要在gdb或mdb中,反汇编一下这个 函数,就能获得函数大小)。
共享Mutex缩小了三分之二左右,代码量大大减小,CPU的消耗也将更加少。当然,Mutex的变化主要体现在内部,对我们维护人员来说无所谓。但还有 些变化是和我们相关的,比如log file sync与log file parallel write的关系等,后面我会找时间写篇文章和大家分享下。
arron刘:
现在云计算和大数据是时代的宠儿,ORACLE也不能置身世外Oracle 12c这个C是不是代表着云计算呢?新的数据库版本在云计算中有哪些应用呢?
VAGE:
其实我理解云就是前些年SAAS的延伸,软件就是服务。以后使用软件,就像电源插座一样,无论到哪里,接上插头就可以使用。Oracle DataBase本身是系统软件,系统软件不必是云。就好像Linux一样,我暂时还无法想像Linux怎么变成云。但系统软件要能很好的支持上层的"云应用"。我觉得12C中的C,是指Oracle将更好的支持上层的"云应用"。
在"云应用"的背景下,数据要有更好的流动性,接上插头、或打开水管,数据就流出来了,"可插拔数据库",是Oracle在这方面的尝试。另外还且个不得不提的东西,就是OGG,虽然它不是在12C中新推出的,但它无疑可以增加数据的流动性。
除了让数据"流"起来之外,应用程序升级到"云应用"后,对数据的规模要求一定越来越大,因此大数据是不可避免的趋势了。其实使用Oracle RAC和ASM,也可以方便的搭建大数据计算平台。
大数据通常都要数据分布化存储,这样才能有更好的扩展性,才能更好的支持大规模数据。
ASM也能实现数据的分布化存储,扩展也可以很方便。而RAC则可以实现分布式计算,也就是多台主机一起进行计算。
比如,先看一张RAC的图:
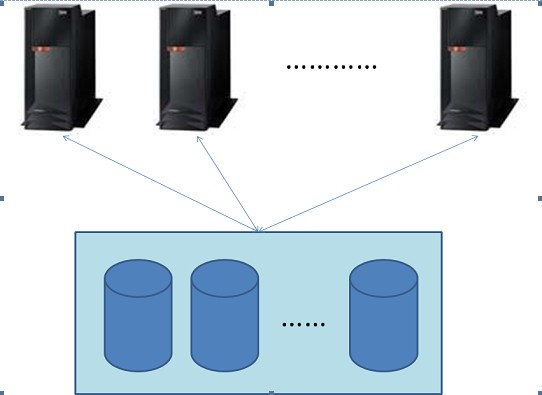
图比较简单,大家凑合着看就行。上面是N个RAC节点,下面是一台共享存储,其中有N块硬盘。这是RAC的传统架构。我主要想通过这幅图表达一个问题,先 不说RAC节点数多对性能的影响,单说RAC的共享存储,一直是RAC的一大限制。共享存储限制了数据的分布性。像GreenPlum和Hadoop等等 都是Nothing Shared的全分布式架构,扩展更方便,能力更强。
其实使用iSCSI+ASM,做一个类似分布式的架构也并非难事,看下图:
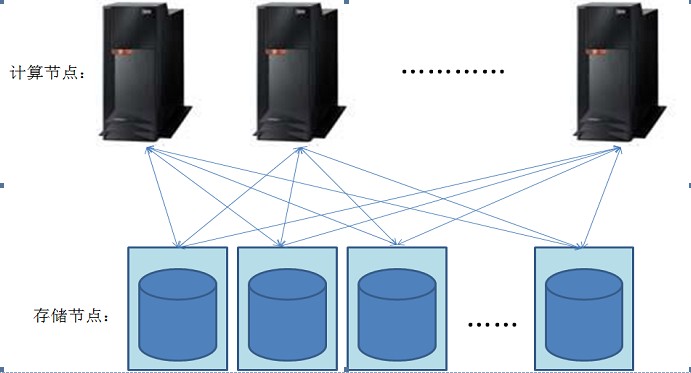
下面的存储节点可以是有很多硬盘的PC Server,每个PC Server的盘用iSCSI技术输送到所有计算节点,然后用这些盘创建ASM的DiskGroup。
以后随着数据空间规模的扩大,只要再接入更多的PC Server,就可以扩展空间了,扩容也很方便。
不过,很多时候,这张图被画成这样:
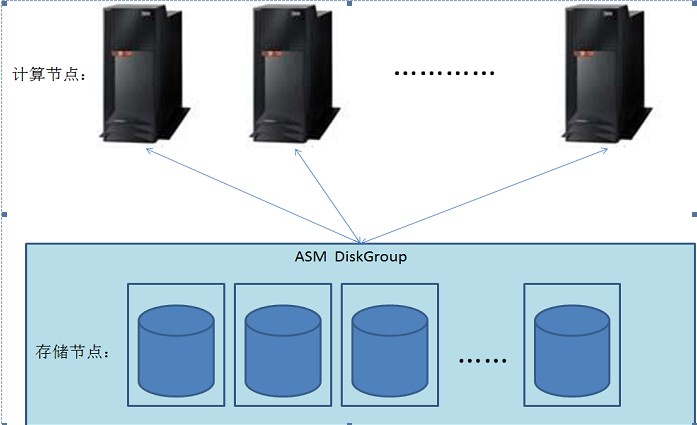
看这张图,还是集中式的架构。一套ASM,集中存放所有数据。其实数据是分布式的。假设在ASM中建一个表,在AU大小1M的情况,这个表的数据会以1M为单位,分布到所有磁盘中。如下图:
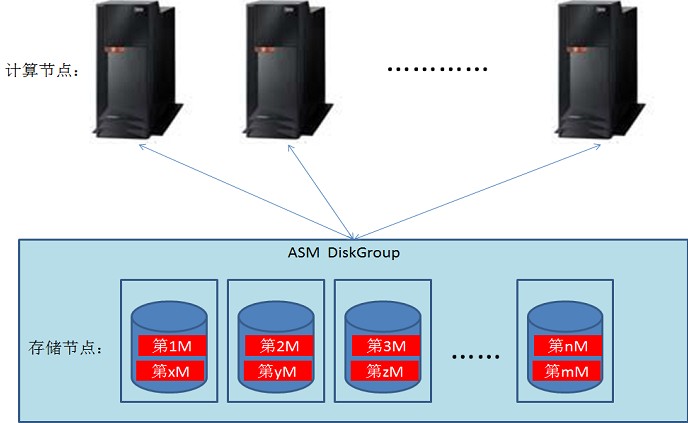
假设在节点1,发起一条命令,对这个表进行全扫描并排序。我们知道,在RAC下,并行操作是会被传播到其他节点的。如上图,也就是说,上图的每个计算节点会一起完成扫描、排序。
在协调节点的控制下,全扫描、排序将按如下图方式完成:
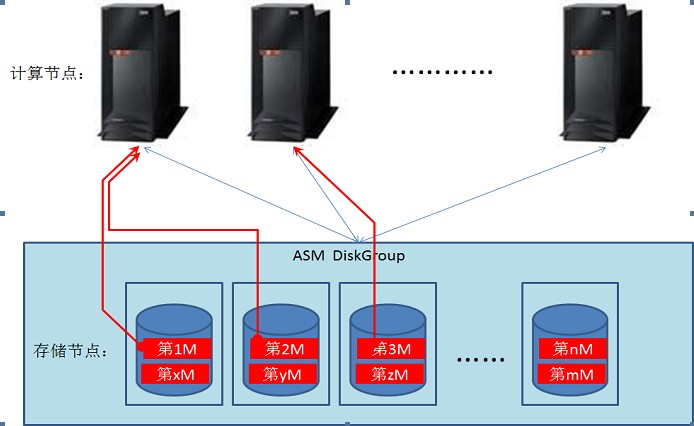
节点1从存储节点1、2中读取第1、2M。同时节点2从存储点3中读第3M,等等。每个计算节点会同时从多个存储节点一起读数据。
多个计算节点,每个都在对一部分数据作操作。每个存储节点,都在为不同计算节点输送数据。简单点说,就像这张图:
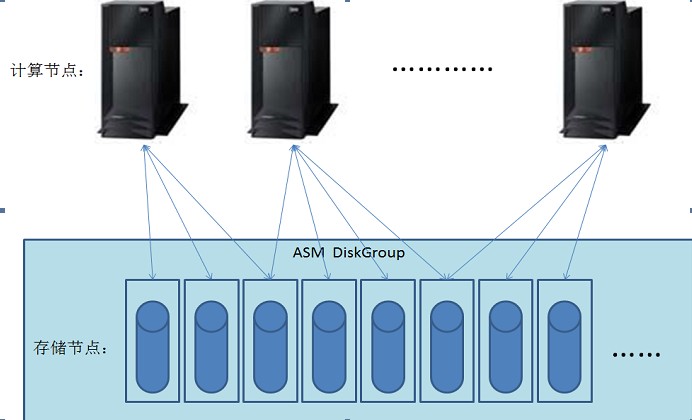
数据分散存储在多台PC Server中,这不就是一套分布式的系统吗!但同时,它又是一套集中式的数据库系统。
试想一下,如果下面的存储节点使用了SSD技术,网络使用和光纤有一比的InfiniBand,这套系统可以提供超大的IOPS,和超高IO吞吐量。
并不一定只有GreenPlum、Hadoop等才是大数据,ASM、RAC也可以实现分布化、大数据。而且,由于对外这还是一个统一的、集中的数据库,这样的方案还有纯分布式不能提供的好处。
还有一个问题:RAC节点数太多的影响。其实RAC节点多少,对整体性能影响不大。节点太多,主要影响稳定性。但Oracle一直在改善多节点的稳定性,相信未来多节点不会是RAC稳定性的瓶颈。
arron刘:
能不能谈谈您在工作中遇见印象比较深的的难题,您是怎么解决的?谈谈您在工作中解决问题的思路?
VAGE:
留给我印象最深刻的难题,说来很搞笑,其实是一个简单的问题。每次提到这个"难题",总让我联想起一个小故事。
说是一家医院,有一段时间总是在凌厚5、6点钟有人病人死亡。经过多方调查,多位专家、牛医汇诊,始终无法找出原因,最后院方重金聘请国内外数位专家学者,组成调查团,入驻医院调查病人死亡原因。最后结果,大大出人意料。
又一天凌晨5点左右,专家已经在病房中开始忙碌起来,检查这个、检查哪个等等的情况,一切都在有条不絮的进行着。这时只见门一开,打扫卫生的阿姨推门进 来,开始打扫卫生。阿姨拔掉电源上的插头,收拾一下零乱的线头,开始拖地、扫地、......。众人过去一看,被拔掉的,赫然有呼吸器的插头。问题终于找到了。
好了,说说我这个案例。这是阿里非常重要的一套核心库,从某天开始,总在11:20分连接数爆涨,偶而有超过processes参数的趋势,不得不手动 Kill掉一些相对不太重要的连接,避免连接数超出。通常两、三分钟后正常。经过调查,发现在11:20分,数据库的各项性能指标(如逻辑读、物理读、解 析次数、执行次数等)先降后升,如下图:
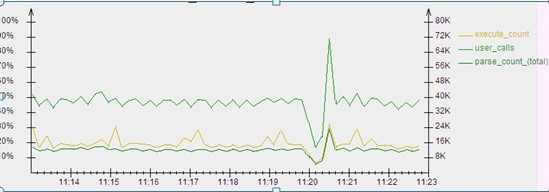
这张图上三项资料的值,执行次数、调用次数、解析次数,在11:19分50秒左右,突然下降,然后在不到一分钟的时间中,又大幅上升。然后,又不到一分钟时间,一切都恢复正常。
黄线是执行次数,在大幅上升的顶点,执行次数有可能超过每秒2.4万次。正是在这个峰值时刻,连接数也达到顶峰。
看到这个图,我当时的判断是,在下降阶段,一定是有什么锁之类的东西,将大家都阻塞了,因此执行次数、逻辑读都大幅下降。之后,"某种锁"释放了,被阻塞的进程一齐要求执行,结果各项性能指标突升。
就好像将河水拦起来,下游没水了,突然将水放开,下游顿时巨浪滔天。然后,蓄的水流完,一切恢复正常。
如何确定问题呢?很简单,既然是某种锁阻塞了大家,只在看等待事件即可。
由于这是9i的库,查不了历史等待事件,只有等第二天再说了。
第二天到了,11:20,情况出现,各项资料先降后升,连接数猛然冲高,然后恢复正常。整个过程,我一直在不停的查看等待事件。但是,什么都没有查到。没有发现所谓的"某种锁"。
哪底是什么问题呢?经过多方调查,DBA、开发、架构、......,各种人员会诊下,问题依旧不明。
第三天11:20分,大家正聚在一起会诊情况,一名开发悠悠的打开电脑、登录VPN、连接应用,开始从一批MySQL集群中拖数据到DW,问题终于找到了,......。
呵呵,当然最后这段有"戏说"的成份,事实情况是,经过分析,根据Oracle没有等待事件判断,性能资料的下降不是由Oracle自身造成的。既然不是 Oracle自身的问题,最大的怀疑对象是网络。经过几天的调查,发现同一机房、同一交换机还连接了一批MySQL。本来MySQL中的数据分阶段向DW 中同步,但可能开发考虑这样一天同步几次太麻烦了,将同步时间改成了每天同步一次,具体时是中午11:20。
这个案例,我想说明的是,当需要网络、MySQL等其他部分同事配合调查问题时,一定要足够的知识、数据,告诉其他部门的同事、领导,"问题不是Oracle",才能获得帮助。
当你向领导汇报说:"问题不是Oracle"。
领导一定会问:"为什么?"。
你回答:"因为没有等待事件。"
这时候,十有八九的领导都会再问:"为什么?"
后面就是发挥的时候了,用简短的语言,解释清楚为什么没有等待事件就说明问题不是Oracle。交流、沟通,永远是我们DBA必不可少的技能。但交流、沟通,并不是全部,还要有过硬的技术作基础。
还有一个案例,有一个RAC,版本是10G的,有一个节点有一段时间经常因为ORA-07445重启,找不到原因。打开当机节点的Trace文件,发现有如下的调用堆栈:
----- Call Stack Trace -----
calling call entry argument values in hex
location type point (? means dubious value)
-------------------- -------- -------------------- ----------------------------
skdstdst()+64 call kgdsdst() 000000032 ? 000000004 ?
ksedst1()+432 call skdstdst() 00000001E ?
ksedst()+128 call ksedst1() C00000123065F668 ?
dbkedDefDump()+1456 call ksedst() 9FFFFFFFFFFFB710 ?
ksedmp()+80 call dbkedDefDump() 000000003 ?
ssexhd()+2672 call ksedmp() 9FFFFFFFFFFFC640 ?
<kernel> call ssexhd() 9FFFFFFFFD54CB68 ?
skgxpdmpmem()+52481 call <kernel> 9FFFFFFFFD54CB68 ?
skgxpgetimd()+51808 call skgxpdmpmem()+48656 C0000017212BC1B9 ?
skgxppost()+27808 call skgxpgetimd()+51104 6000000000043FA0 ?
skgxpvsnd()+11696 call skgxppost()+23936 9FFFFFFFFFFFD340 ?
skgxpwait()+512 call skgxpvsnd()+7104 9FFFFFFFFFFFECB0 ?
ksxpwait()+2928 call skgxpwait() 000000032 ? 000000004 ?
$cold_ksliwat()+203 call ksxpwait() 00000001E ?
kslwaitctx()+240 call $cold_ksliwat() C00000123065F668 ?
kslwait()+192 call kslwaitctx() 9FFFFFFFFFFFB710 ? 000000003 ?
ksxprcvimd()+1120 call kslwait() 000000003 ?
........................
正好哪段时间我一直在研究Oracle的等待事件机制。Kslwait、skgxpwai等等这些函数正是Oracle产生等待事件的函数。Trace文 件是Lms进程的,看问题是lms产生了某个等待事件,在登记等待事件后出的问题。如果能知道lms当时产生的等待事件是什么,问题应该就有了方向。
但是查看了相关的Trace文件,找不到当时的等待事件。最后的方法很简单,使用oradebug中的call命令,调节ksxpwait函数,参数是 000000032,000000004等。然后查询oradebug的会话在等待什么,发现它在等一个不常见的I/O类等待事件(具体事件名记不太清楚 了)。由此判断,是I/O导致的问题。最终发现是存储多路径软件版本的问题。
综合这两个案例,解决Oracle问题,无外乎也就技术、沟通这两点而已。
arron刘:
现在数据库技术更新换代的速度越来越快了,您觉得从业者该怎么选择自己的学习方向?比如说应该学习什么数据库之类的问题。
VAGE:
我觉得这个要看个人爱好了,有兴趣研究源码的,我觉得去研究一下MySQL、PostGreSQL等等,是个不错的选择。如果对代码不感兴趣,那就选择Oracle好了。
当然,还有Hadoop类的NoSQL类方面,也是值得考虑的。如果年龄还不算大、还有时间的话,可以都接触下,看一下兴趣点在哪里。毕竟,学习是很苦的事情,如果不能发掘点兴趣出来,是很难坚持的。
另外,虽然现在是个一专多能的时代,但在选择方式时最好还是要有所选择。有些专业,加在一起可以起到双剑合璧的效果,威力翻倍。但有些专业,多会一样,可 能只代表工作量会翻倍。比如开发和美工。美工设计出的界面有可能脱离程序,开发设计出的界面有可能脱离用户。开发+美工,等于界面设计师。好的界面要由界 面设计师设计。界面设计师编码能力一般,美工能力也不要求多高。界面设计师如果单纯从事开发的工作,或美工的工作,收入都比较低。但将开发、美工二者结合 后,收入将会提高很多。选择方向的时候,其实不仿考虑一下,哪个方向和自己现在的工作结合度更高。哪个方向可以和自己现在的专业"双剑合璧"。
arron刘:
您作为行业的老人,不知道有没有遇见过学习瓶颈的问题?您面对这种问题是怎么解决的呢?有没有什么好的方法分享一下。
VAGE:
学习瓶颈啊,我已经遇到过好几次了。第一次瓶颈是在学习编程7年之后,大概是2003年。我个人比较偏爱C语言,公司有些项目是SDK开发的,使用的是C语言。但更多项目是使用的5花八门的语言。
就像现在很多人苦恼一样,公司里用Oracle,就学Oracle。业务上有MySQL,就再学MySQL,还有SQL Server等等,结果会了一大堆数据库。
我当时是事业单位的临时工,为了不被辞掉,我甘当一颗革命的螺丝钉,哪里需要哪里拧。为了单位需要,我学习了C++、Visual FoxPro、Java、VBScript、JavaScript,还有Oracle的Form/Report。更离谱的还有Flash中的脚本编程。
这样广泛涉猎多年之后,我发现很多专一的人已经比我牛B太多,牛B的我连想去超越的勇气都没有了。我觉得编程上自己很难再有成果,很难再前进。决定换个方向,这个新的方向就是Oracle了。正好单位也需要Oracle方面的人,我又一次充当了革命的螺丝钉。不过,痛定思痛,这一次我决定专一点,只搞 Oracle。
这样又过了8年,在我到阿里后第二年,当时觉得Oracle真没什么可学的了。雾里看花的研究内部原理,如同隔靴搔痒,很多地方总感觉没办法研究透。只能在网上搜各程各样的文章,讨论起原理总是说谁谁的文章中提到过,某篇内部资料说了,这个地方应该怎么怎么样。感觉DBA有点像考据学家了,整天查这个资料、翻哪个资料,一开口就是,史记第几章提到什么什么,汉书第部分讲了什么什么,因此怎样怎样。
关键是这样的研究,由于无法了解透某些技术的原理,在真出问题的时候,意义不大。所以当时我非常同意一个观点:内部原理的研究,应当适可而止,再深入下去只是满足好奇心,对于调优排故帮助不大。
我觉得是时候"适可而止"了。这是我第二次遇到瓶颈。
当是也迷茫了好久,本来计划另选新的方向,比如MySQL、Hadoop等等。但偶然的机制发现Dtrace后,用这东西研究原理,发现很多原来无法搞清楚的东西,可以搞的比较透了。再后来又结合gdb/mdb,可以将内部机制了解的更加清楚。
一旦可以通透的了解机制,对于DBA帮助还是非常巨大的。最明显的一个好处,一些等待事件、v$sysstat中的资料,其根本意义将更加清楚的展现在你眼前。
举个简单例子,Oracle有两个简单的网络相关等待事件,"SQL*Net message to client"和"SQL*Net more data to client",一个是Message to Client,一个是More data to client。这二者有什么区别?
我们都知道Oracle有一个"预读取",或叫"批量读"的功能,在SQL*Plus中可以用set arraysize 设置批量读的批大小。在SQLPLUS中默认值是15,也就是一次逻辑读默认读15行。
逻辑读的数据是发何发送给客户端的呢?这些数据要先被读取出来,暂时存入PGA的一块名叫Session Data Unit(简称SDU)的空间,再从SDU中通过网络发送给客户端。
SDU默认大小是8K,如果一次逻辑读读出的数据小于SDU大小,等待事件是"SQL*Net message to client"。如果一次逻辑读的数据大于SDU,数据将被分多次发送,这时将会有等待事件"SQL*Net more data to client"。具体来说,比如一次逻辑读的数据共10K,而SDU是8K,这将会产生一次"SQL*Net more data to client",一次"SQL*Net message to client"。
关键问题是,数据已经占满SDU,这时加在数据块对应Buffer上的Buffer Pin锁不会释放,因为一次逻辑读还没有完成。数据通过网络发送,同时进程注册等待事件"SQL*Net more data to client"。发送完数据,继续逻辑读。直到这个块Buffer中的数据被读完、或者达到一个批大小,Buffer Pin锁才释放。
也就是说,Buffer Pin锁的持有,在有等待事件"SQL*Net more data to client"时,包含了网络的传输。这将导致Buffer Pin锁持有时间加长,有可能触发Buffer Busy Waits相关等待。
简单点说,批量读批大小超过SDU,将会有"SQL*Net more data to client"。没超过是"SQL*Net message to client"。而有"SQL*Net more data to client",则说明进程将在块Buffer上持有更长时间的Buffer Pin锁。
SDU的大小,虽然默认是8K,但它是可调的。关于它,在文档"Net Services Reference",第5章中,和文档"Net Services Administrator's Guide"第7章中,都有介绍。我将"Net Services Administrator's Guide"第7章中的粘下来,这一段还比较详细:
Session Data Unit (SDU) Size
Before sending data across the network, Oracle Net buffers and encapsulates data into the session data unit (SDU). Oracle Net sends the data stored in this buffer when the buffer is full, flushed, or when database server tries to read data. When large amounts of data are being transmitted or when the message size is consistent, adjusting the size of the SDU buffers can improve performance, network utilization, or memory consumption. You can deploy SDU at the client, the application Web server, and the database server.
说实话,这段英文看的我莫明其妙。很早之前我看这段话的时候,完全无法理解SDU的真正影响与作用。
SDU到底控制着什么,调节它的大小可以影响性能,影响什么性能?影响有多大?......,有N多的问题,文档中都没有提到。
没有提的原因无外乎有两个:一是信息垄断。只有内部人士可以掌握更多的信息,现代社会,信息就是金钱啊,相信Oracle有理由这么做的。
不过,这个调节参数是在sqlnet.ora等监听配置文件中调的,如果真是为了限藏它,干脆在文档中不提多好。
如果文档不提,用户用show parameter或查隐藏参数的视图,又找不有这么个东西。这样多好,除了内部人,其他人断无可能知道有这么个东西。
文档即然提了,又没讲清楚,我想还有另一个原因,就是写的文档的人也不知道这东西是干吗的,从以前版本的文档中直接照抄过来完事。
我原来在网上也了解过这个参数。一些个老外也有提到过这个东西,但都没有说清楚。
说白了SDU很简单,加大SDU大小,可以将"SQL*Net more data to client"等待事件变成"SQL*Net message to client"事件,减少Buffer Pin锁的持有时间,节省CPU。
使用gdb/mdb和Dtrace,非常简单就可以将SDU的意义发觉出来。我就是在一次调试Oracle时,发现进程运行代码中,一会注册 "SQL*Net more data to client"等待事件,一会注册"SQL*Net message to client"等待事件。进一步分析,发现读取数据量超过8K时,就会有"SQL*Net more data to client"等待事件。然后在文档中查了一下,SDU的默认值是8K,修改了这个值,果然可以去掉"SQL*Net more data to client"等待事件。因此发现SDU的作用,过程也很简单。
有时间再和大家详细分享这个结果吧。继续讨论"瓶颈"的问题。我的第二次瓶颈,就是在发现调试工具可以用于Oracle后打破的。软件调试+Oracle,这是我给自己设定的一个新方向。
软件调试也是一个大方向,需要了解很多东西。比如,操作系统原理,这是必不可少的。《深入理解Linux内核》,《深入理解Solaris内核》,这些书是要大概翻翻看的。
就像现在流行的量子物理一样,人类的一憋,确定了量子的位置。作为观测者的人娄,对被观测对象亚原子,是有影响的。计算机也一样,调试也会影响到调试对象。但影响到底在哪里,这些只有在对操作系统原理有基本的了解后,才能明白。
Linux下还有一个调试利器:Ptrace,Gdb就是用这东东实现的。还有CPU的一些相关知识,这些都要去学。
学好调试这块,真的要进入底层了。
不过,这样的学习收获是很大的。对计算机底层有基本的了解,这是每个IT技术人员的基本要求。如果我们对CPU、内存等等的了解,只停留在频率、型号上, 这样的话我们和电脑城买电脑的也差不多了。但人家是销售,我们好歹也是技术人员。你说一技术人员对内部的了解和销售差不多,有点说不过去吧。而且,基础知识不足的话,也很容易有一些让开发笑话的观点。
曾有人不太理解一种CPU负载的计算方式:逻辑读块数乘以块大小。
逻辑读的确是消耗CPU的操作,但一个复杂的数据库可不只逻辑读消耗CPU。而且,一个逻辑读可不一定都是读8K,有可能只是从8K中只读几十个字节。逻辑读块数乘8K,这样的统计方式的确有点莫明其妙了。如果对计算机底层基础知识有些了解的话,对于这样的错误结论是很容易理解的。
调试+Oracle估计够我再学个一、两年的了,哪天瓶颈再到了,我计划自己写写数据库玩玩,最近看了老虎的帖子:用数据库的称为大师,写数据库的笑了......^_^,心痒难耐,等我的书稿完成后,下半年我也响应虎皇号召,去搞搞这块。
历史上的今天...
By eygle on 2013-07-31 13:05 | Comments (0) | 人物传奇 | 3117 |