
June 12, 2024
MySQL 第一个版本的正式发布时间
关于 MySQL 的历史,有很多不同的描述,但是无疑MySQL AB的创始人阐述的最为准确和可靠。
David Axmark 和 Michael Widenius 在《MySQL Introduction》一文中这样记录了过去:
In May 1996, MySQL version 1.0 was released to a limited group of four people, and in October 1996, MySQL 3.11.1 was released to the public as a binary distribution for Solaris. A month later, a Linux binary and the source distribution were released. The MySQL release included an ODBC driver in source form. This also included many free MySQL clients ported to MySQL.
1996年5月,MySQL 1.0版本发布,仅限四人使用。1996年10月,MySQL 3.11.1版本作为Solaris系统的二进制分发版向公众发布。一个月后,发布了Linux的二进制版本和源代码分发版。MySQL发布包括了以源代码形式提供的ODBC驱动。这也包括了许多移植到MySQL的免费MySQL客户端。
参考链接:https://dl.acm.org/doi/fullHtml/10.5555/328036.328041
Posted by eygle at 9:18 AM | Permalink | FAQ (270)
May 29, 2024
循序渐进MogDB:如何通过copy转储表数据到CSV文件
在 MogDB 数据库中,通过 copy 命令可以灵活的将数据复制到数据库中,或者,将表数据转储到磁盘文件。当转储文件时,也可以通过 with 子句指定具体的参数,实现多样化输出文件的支持。
以下是一个范例,通过 with 语句,可以指定导出数据的分隔符(delimiter),是否包含头文件信息等:
MogDB=>copy student to '/home/omm/student.csv' with (format csv,delimiter ',',header on);
COPY 5467MogDB=>copy people to '/home/omm/people.csv' with (format csv,delimiter ',',quote '"',header on);
COPY 518
当然,也可以使用 MogDB 的客户端工具,Mogeaver] 的 Data Transfer 功能进行数据的转换。Mogeaver 的好处是,可以分批次提交,减少内存的耗用。
向数据库中加载 CSV 文件参考:
循序渐进MogDB:通过 copy 加载 CSV 文件到数据库
Posted by eygle at 10:04 AM | Permalink | Beginner (56)
October 18, 2023
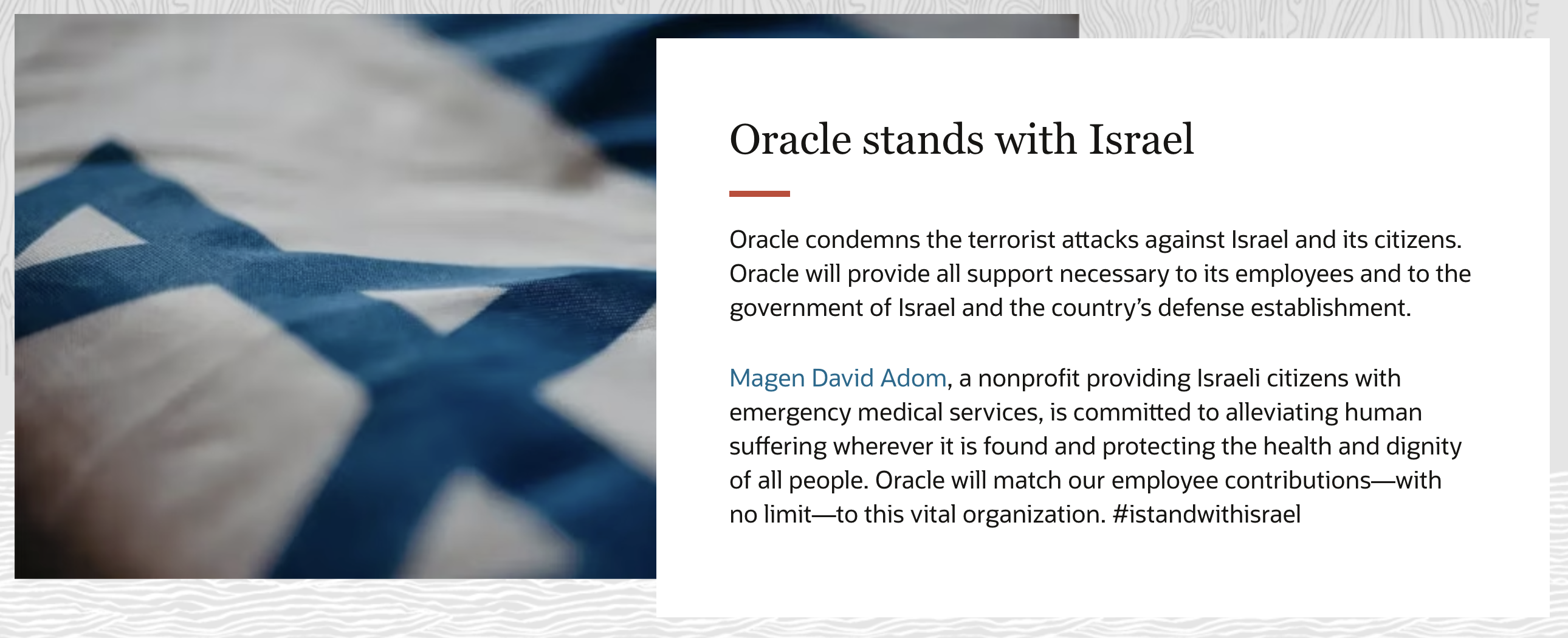
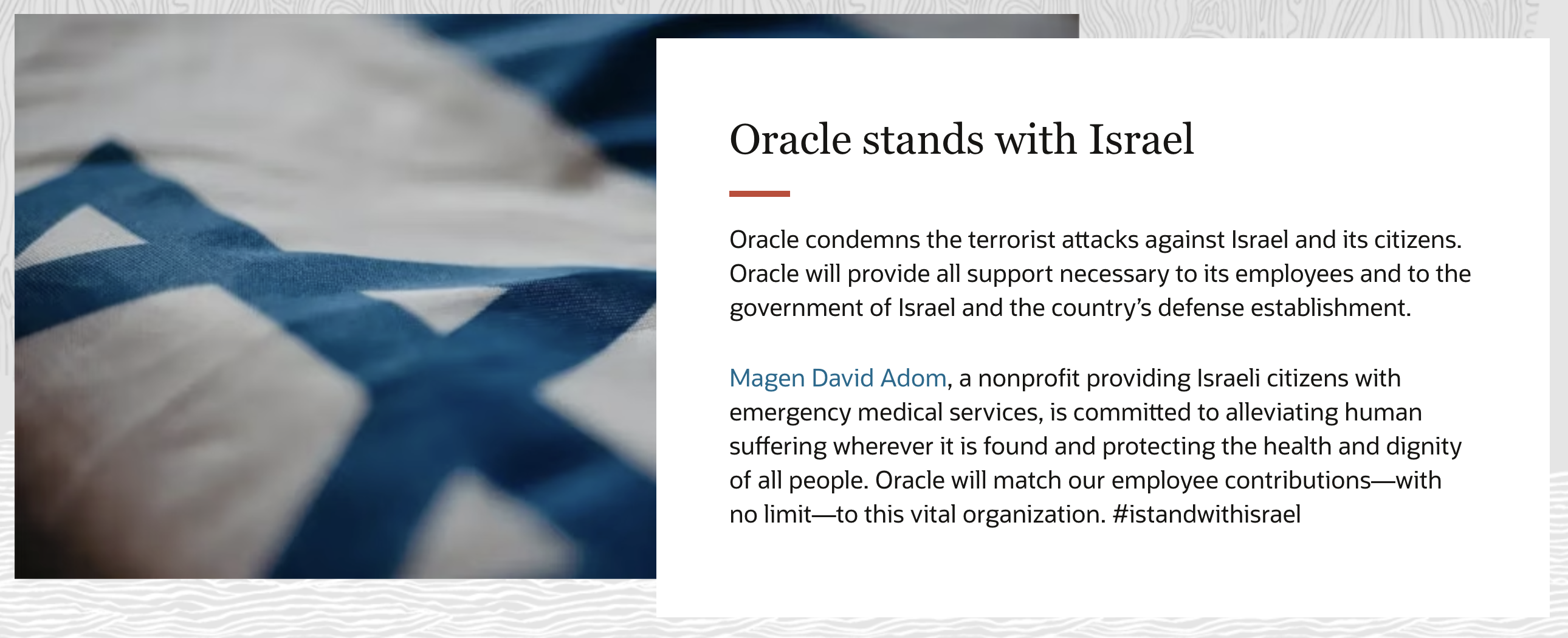
官网更换首页:Oracle旗帜鲜明表明立场支持以色列
Oracle谴责针对以色列及其公民的恐怖袭击。Oracle将为其员工、以色列政府和国防机构提供一切必要的支持。
Magen David Adom是一家为以色列公民提供紧急医疗服务的非营利组织,致力于减轻任何地方的人类痛苦,保护所有人的健康和尊严。Oracle将为员工向这一重要组织的捐款提供等额资助。
{kind=link}
此前,Oracle已承诺向Magen David Adom捐赠100万美元,并正在发起一场活动,鼓励其15万名员工捐款,Oracle还将为员工捐款实现等额捐助。Oracle首席执行官萨夫拉·卡茨(Safra A. Catz)公开谴责了这些袭击。
Safra A. Catz,出生于以色列,小时候随家人移民到美国,她能讲流利的希伯来语。Catz 自1999年4月起担任甲骨文公司高管,自2001年起担任董事会成员。2011年4月,她被任命为联席总裁兼首席财务官,向创始人拉里·埃里森汇报工作。2014年9月,甲骨文宣布埃里森将辞去首席执行官一职,马克·赫德和卡茨已被任命为联合首席执行官。2019年9月,赫德因健康问题辞职后,卡茨成为唯一的首席执行官。
此外,众所周知,Oracle公司的创始人 Larry Ellison有一半的犹太血统,他母亲是犹太人,父亲是一个意大利飞行员。
Catz 曾经公开表达说:"当你与Oracle公司联系时,你就会明白我们对美国和以色列的承诺。我们对自己的使命没有丝毫弹性,我们对以色列的承诺是首屈一指的。这是一个自由的世界,我爱我的员工,如果他们不同意我们支持以色列国的使命,那么也许我们公司不适合他们。拉里和我公开承诺支持以色列,并将个人时间投入到这个国家,任何人都不应该对此感到惊讶。"
Oracle公司向来旗帜鲜明,这一次也毫不例外。不谈立场,让我们共同期待世界和平。
Posted by eygle at 4:16 PM | Permalink | OraNews (268)
September 30, 2022
Oracle Database 23c 新特性: 基于别名和位置的 GROUP BY 简化
在Oracle Database 23c 中,group by 作出了一个期待已久的增强,支持通过别名或者位置的Group by 查询。
在23c之前,group by 要不断重复查询中的复杂逻辑,如下所示:
SELECT EXTRACT(year FROM hiredate) AS hired_year, COUNT(*) from emp
GROUP BY extract(year FROM hiredate) HAVING extract(year FROM hiredate) > 1985;
在23c中,可以通过别名大大简化这一SQL:
SELECT EXTRACT(year FROM hiredate) AS hired_year, COUNT(*) from emp
GROUP BY hired_year HAVING hired_year > 1985;

这是开发者期待已久的,终于在 23中得以实现。
Posted by eygle at 9:18 AM | Permalink | Oracle12c/11g (177)
September 28, 2022
Oracle Database 23c 新特性:4096 列支持和 Schema 权限一次授予
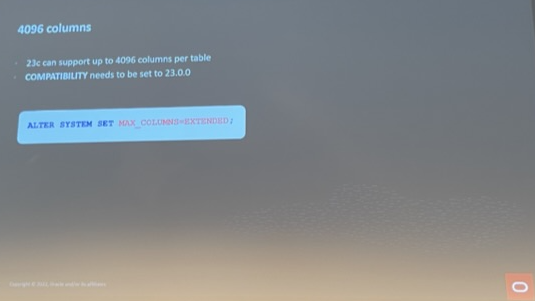
我们知道 MogDB 单表最大支持 1600 列,Oracle 此前版本单表支持 1000列。
在23c中,单表支持列数量扩展到 4096 列。启用这一个特性需要将兼容性参数设置为23.0.0,同时将 Max_columns设置为 Extended:
alter system set MAX_COLUMNS=EXTENDED;
在23c之前的版本,如果针对 Schema 对其他用户进行授权,需要通过系统权限 或 对象权限 分别显示的授予,这对数据库带来了额外的安全风险 或 复杂性。
在 Oracle 23 中,可以对 Schema 进行授权,简化了之前的全线操作:
grant select any table on SCHMEA PROD to HR;

详情参考:Oracle Database 23c 十小新特性速览:从Schema权限到4096列支持
Posted by eygle at 3:33 PM | Permalink | Oracle12c/11g (177)
近期发表
CopyRight © 2004 ~ 2012 eygle.com, All rights reserved.