
« Oracle 20c 新特性:expdp / impdp 数据泵EXCLUDE和CHECKSUM | Blog首页 | HP DESKJET 2130 / 2138 MAC 安装解决打印问题 »
Oracle 20c 新特性:XGBoost 机器学习算法和 AutoML 的支持

链接:https://www.eygle.com/archives/2020/05/oracle_20c_xgboost_automl.html
Oracle 20c数据库中引入的一个新的机器学习算法叫做XGBoost。XGBoost是一个开源软件库,它在大多数常用的数据科学、机器学习和软件开发语言中提供了一个梯度提升框架。
该算法是在之前的决策树、Bagging、随机森林、Boosting和梯度提升等工作的基础上发展而来。XGBoost 是一个高效、可扩展的机器学习算法,经过多年的研究、开发和验证,XGBoost可以用于分类的典型用例,包括分类、回归和排名问题(regression and classification)。
OML4SQL XGBoost (Oracle Machine Learning for SQL XGBoost) 是一个可扩展的梯度树提升系统,支持分类和回归。它提供了开源的梯度提升框架。通过准备训练数据,调用XGBoost,构建和持久化模型,并应用该模型进行预测,使得XGBoost Gradient Boosting开源包在数据库中可用。
你可以将XGBoost作为一个独立的预测器使用,也可以将其整合到实际的生产流水线中,用于广告点击率预测、危害风险预测、网页文本分类等多种问题。
OML4SQL XGBoost算法需要三种类型的参数:通用参数、助推器参数、任务参数。用户通过模型设置表来设置参数。该算法支持大部分开源项目的设置。
通过XGBoost,OML4SQL支持多种不同的分类和回归规范、排名模型和生存模型。在分类机器学习函数下支持二进制和多类模型,而在回归机器学习函数下支持回归、排名、计数和存活模型。
为什么 XGBoost 如此受到欢迎?
XGBoost 是基于决策树的集成机器学习算法,它以梯度提升(Gradient Boost)为框架。在非结构数据(图像、文本等)的预测问题中,人工神经网络的表现要优于其他算法或框架。但在处理中小型结构数据或表格数据时,现在普遍认为基于决策树的算法是最好的。下图列出了近年来基于树的算法的演变过程: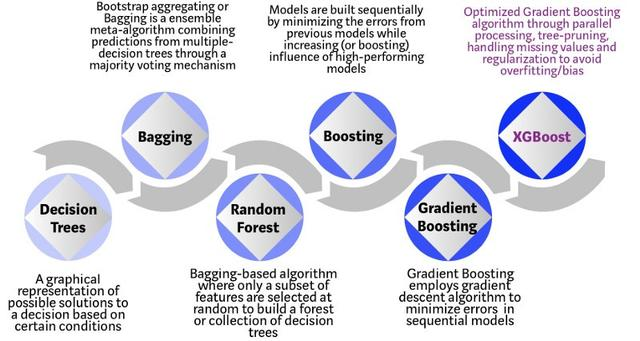
XGBoost 算法最初是华盛顿大学的一个研究项目。陈天奇和 Carlos Guestrin 在 SIGKDD 2016 大会上发表的论文《XGBoost: A Scalable Tree Boosting System》在整个机器学习领域引起轰动。自发表以来,该算法不仅多次赢得 Kaggle 竞赛,还应用在多个前沿工业应用中,并推动其发展。许多数据科学家合作参与了 XGBoost 开源项目,GitHub 上的这一项目约有 350 个贡献者,以及 3600 多条提交。和其他算法相比,XGBoost 算法的不同之处有以下几点:
- 应用范围广泛:该算法可以解决回归、分类、排序以及用户自定义的预测问题;
- 可移植性:该算法可以在 Windows、Linux 和 OS X 上流畅地运行;
- 语言:支持包括 C++、Python、R、Java、Scala 和 Julia 在内的几乎所有主流编程语言;
- 云集成:支持 AWS、Azure 和 Yarn 集群,也可以很好地配合 Flink、 Spark 等其他生态系统。
算法演进过程:
- 常规的机器学习模型(例如决策树)仅使用训练数据集来训练单个模型,并且仅将此模型用于预测。尽管决策树的创建非常简单(并且非常快),具有模型可解释性,但其预测能力可能不如大多数其他算法好。
- 为了克服此限制,可以使用集成方法创建多个决策树,并将其组合以用于预测目的。
- Bagging算法(英语:Bootstrap aggregating,引导聚集算法,又称装袋算法)是一种使用多数表决将来自多个DT模型的预测进行合并的方法。
- 在装袋方法的基础上,Random Forest使用功能的不同子集和训练数据的子集,以不同的方式将它们组合以创建DT模型的集合,并作为一个模型呈现给用户。
- Boosting通过建立顺序模型与每个后续模型的方式,采用一种更迭代的方法来完善模型,其重点是最大程度地减少先前模型的误差。
- 梯度提升使用梯度下降算法来最小化后续模型中的误差。
- 借助XGBoost,可以在上述步骤的基础上进行并行处理,树修剪,数据丢失处理,正则化以及实现更好的缓存,内存和硬件优化。通常称为梯度增强。
通过以下几个示意图,我们可以大致了解一下以上提到的各种 ML 算法。
-
决策树,以非常快速的、可解释的模型,来进行判断选择,支持决策

-
多决策树,用于组合预测,增加准确性

-
Bagging 算法,也就是所谓的 装袋算法
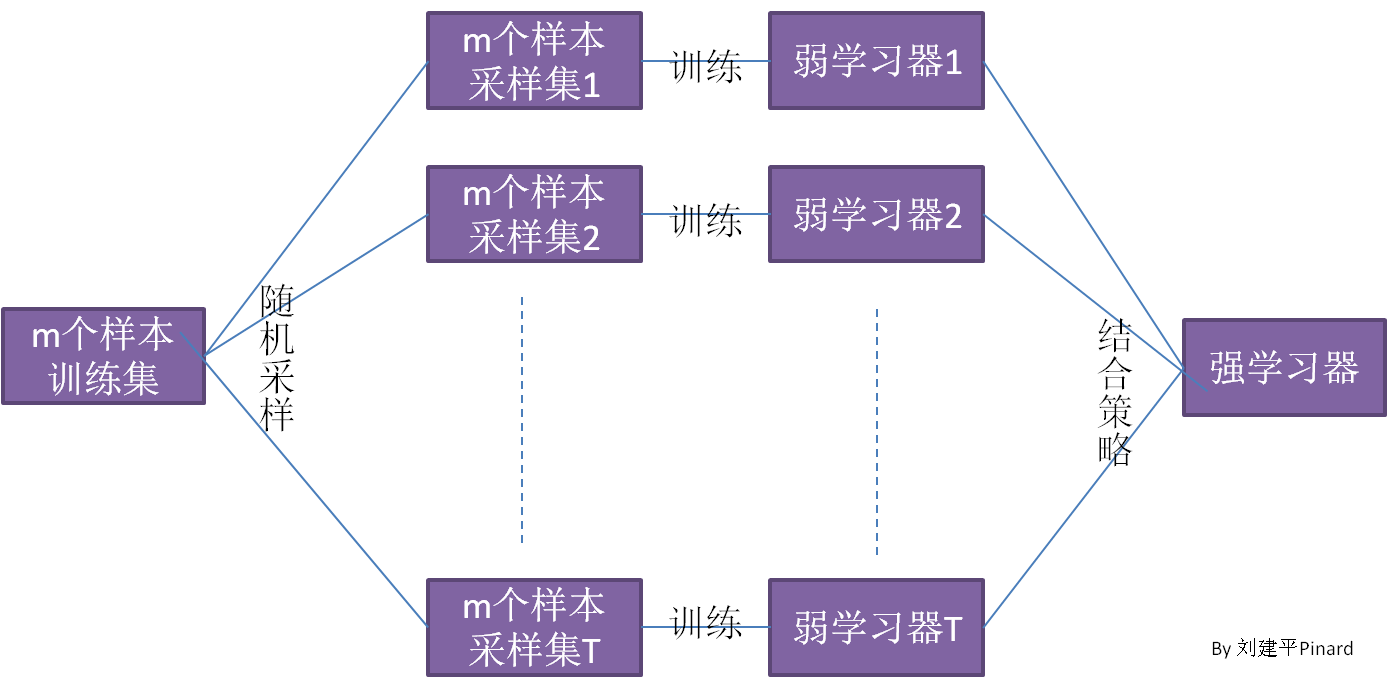
Bagging 特点在"随机采样"。随机采样(bootsrap)就是从训练集采集固定个数的样本,但是每采集一个样本后,都将样本放回。也就是说,之前采集到的样本在放回后有可能继续被采集到。 -
Random Forest ,随机森林 算法
RF在实际中使用非常频繁,其本质上和bagging并无不同,只是RF更具体一些。一般而言可以将RF理解为bagging和DT(CART)的结合。随机森林是由很多决策树构成的,不同决策树之间没有关联。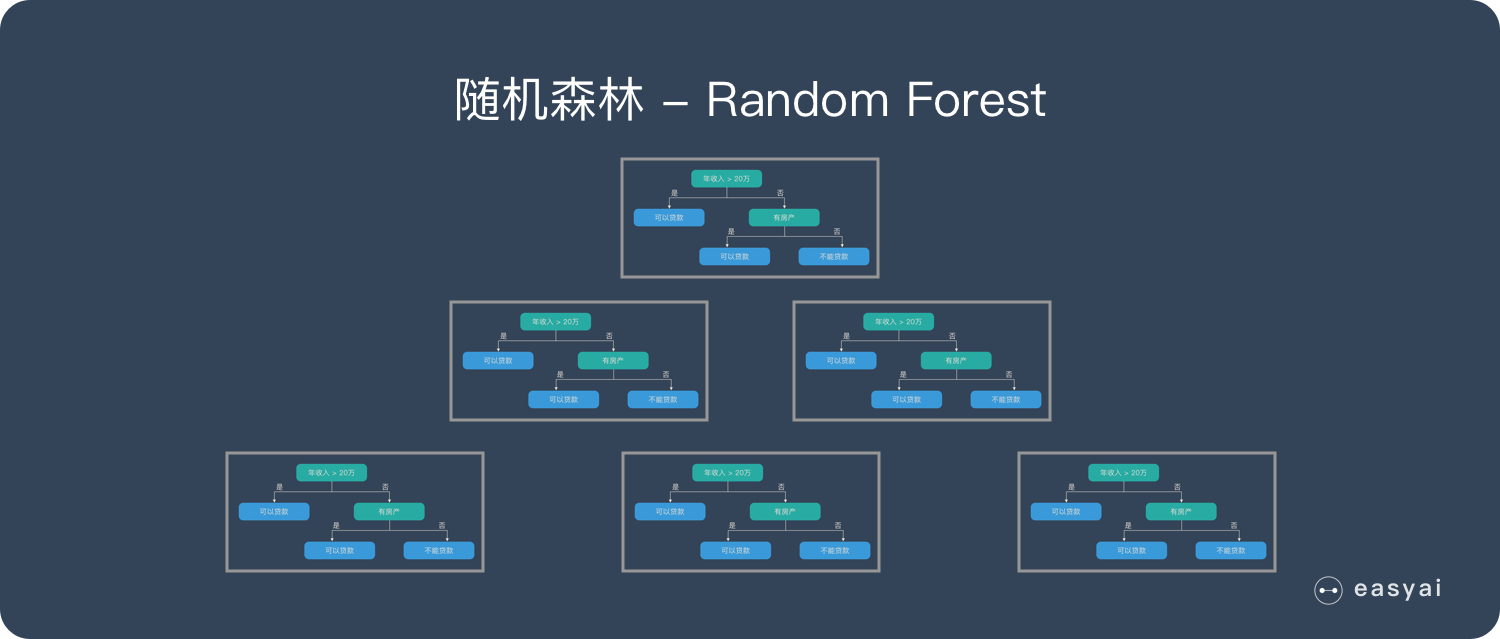
RF中的基学习器使用的是CART树,由于算法本身能降低方差(variance),所以会选择完全生长的CART树。抽样方法使用bootstrap,除此之外,RF认为随机程度越高,算法的效果越好。所以RF中还经常随机选取样本的特征属性、甚至于将样本的特征属性通过映射矩阵映射到随机的子空间来增大子模型的随机性、多样性。RF预测的结果为子树结果的平均值。RF具有很好的降噪性,相比单棵的CART树,RF模型边界更加平滑,置信区间也比较大。一般而言,RF中,树越多模型越稳定。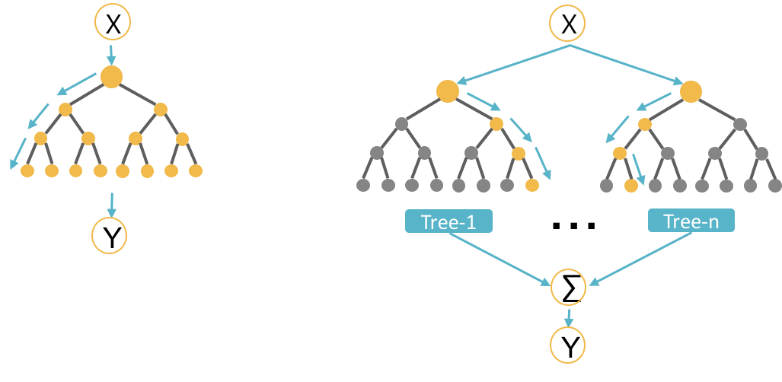
-
Boosting
Boosting 和 bagging 最本质的差别在于他对基础模型不是一致对待的,而是经过不停的考验和筛选来挑选出「精英」,然后给精英更多的投票权,表现不好的基础模型则给较少的投票权,然后综合所有人的投票得到最终结果。大部分情况下,经过 boosting 得到的结果偏差(bias)更小。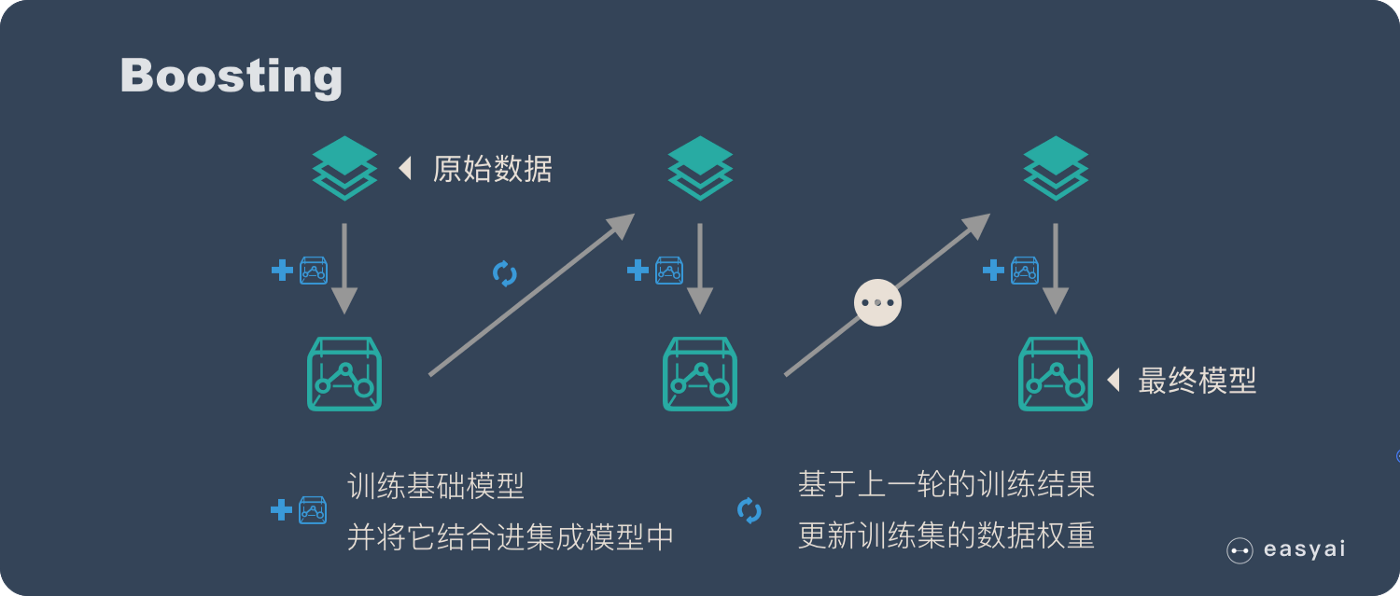
-
梯度提升树算法
梯度提升树算法实际上是提升算法的扩展版,在原始的提升算法中,如果损失函数为平方损失或指数损失,求解损失函数的最小值问题会非常简单,但如果损失函数为更一般的函数(如绝对值损失函数或Huber损失函数等),目标值的求解就会相对复杂很多。
梯度提升算法,是在第
历史上的今天...
>> 2011-05-09文章:
>> 2008-05-09文章:
>> 2007-05-09文章:
>> 2006-05-09文章:
>> 2005-05-09文章:
By eygle on 2020-05-09 15:53 | Comments (0) | Oracle12c/11g | 3394 |